AI pentest report analysis - part one: designing an agentic solution
Slash pentest report analysis time (and costs) with smart AI agents that do all the heavy lifting

Parsing and transcribing penetration test (pentest) report findings into a ticketing system is a tedious, manual task. On average, it takes about 5 minutes to copy and paste a single finding - including text, formatting, and images - into Jira or a similar platform.
Suppose a report contains just five findings, this already adds up to around 30 minutes of manual work. Bump up to 10 findings, a reasonable average, and you’re looking at over an hour spent on tedious copy-paste tasks. Now, consider this: if you’re paying a security engineer a total compensation of around USD 170K, and your company runs at least four pentests a year, you’re burning through roughly USD 325 annually on manual report handling alone. That may not sound like a high amount, but it’s likely a very conservative estimate.
The actual cost varies significantly based on salary bands (depending on location), company size, the number of products being tested, and how often pentests are conducted. For instance, if your company has three products and each undergoes six pentests a year, you could spend up to 900 hours annually just copying findings from reports (calculated as 5 minutes x 10 findings x 6 pentests x 3 products). At a salary of USD 170K, that translates to roughly USD 74K a year in wasted productivity. By automating this kind of manual work, you’re not just saving money, you’re also preserving the mental energy and focus of your highly paid security engineers.
Programmatically extracting findings from PDF reports is no trivial task. Formats vary widely, and every pentest vendor adopts their unique reporting structure. At its core, it’s a classic case of trying to extract structured data from fundamentally unstructured sources.
Solution overview
To reduce analysis time and costs, the simplest and most effective solution is to use an AI agent to analyse pentest reports and extract findings in a structured format. This process can be automated with a lightweight, locally running Python script. We’ll use Python to code the script, LlamaIndex to create the AI agent, and Jira to upload the extracted findings. The diagram below illustrates the high-level architecture of this agent-driven workflow:
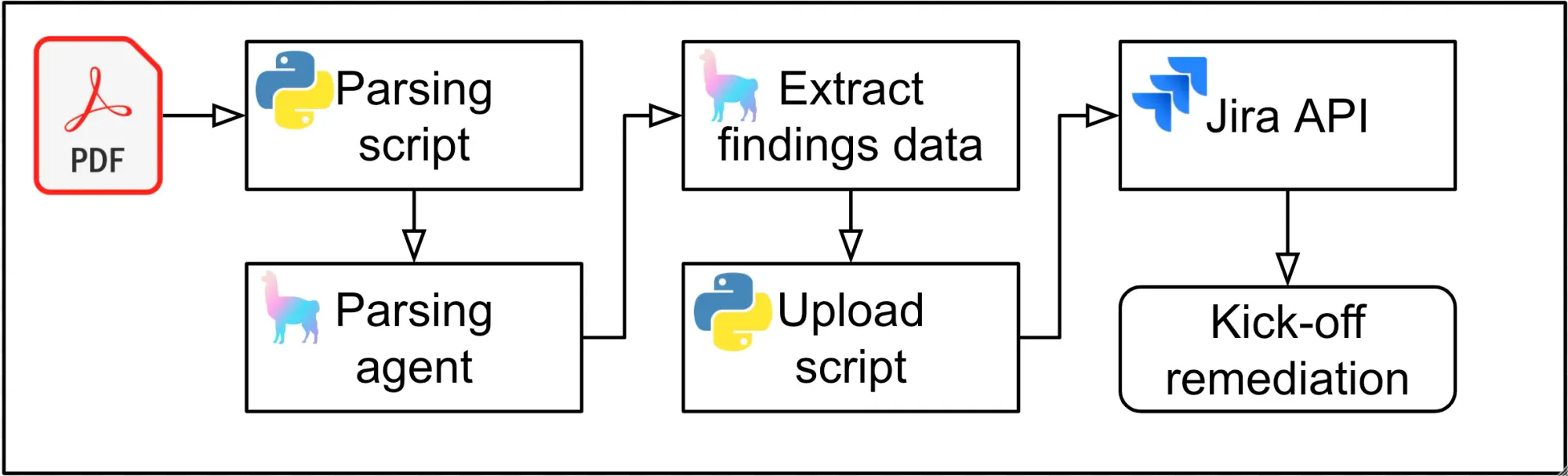
AI agents powered by large language models (LLMs) offer superior performance when parsing and extracting structured data from unstructured PDFs. Unlike software scripts that rely on fixed rules like regex or XPath, LLMs can understand natural language, infer context, and adapt to variations in formatting. This makes them far more reliable for handling real-world documents like pentest reports, where data placement is often inconsistent and unpredictable.
LLMs also excel at processing noisy text with unpredictable formatting, which frequently causes conventional parsers to fail. They can work across multiple languages and formats without needing separate scripts, reducing development overhead. By using an agent, we can minimise manual effort, scale rapidly, and automatically adapt to new document templates. While traditional methods may still work for highly structured, static formats, LLMs offer a faster and more flexible solution for extracting structured insights from unstructured sources.
LlamaIndex is a company that provides powerful tools to build AI knowledge assistants that connect enterprise data sources to large language models (LLMs). It streamlines the process of ingesting, structuring, and querying data from sources like PDFs, databases, APIs, and more using popular LLMs. Moreover, LlamaIndex provides tools to rapidly integrate with LLM APIs from OpenAI, Google, Mistral, Anthropic and many others, allowing developers to tap into the best AI models available.
It also offers a specific product called LlamaExtract (currently in Beta), providing specialist agents designed to pull information from unstructured documents, PDFs and other raw text sources. Additionally, LlamaIndex gives developers full implementation control, supporting the integration of both cloud-based and on-premises LLMs through Ollama.
Building the agent
We’ll build our agent using the llamaextract python software development kit (SDK). While coding an AI agent might sound complex, LlamaExtract makes it surprisingly straightforward: our entire solution will take fewer than 50 lines of clean, readable Python. In addition to the LlamaExtract SDK, we’ll use a few other helpful Python libraries:
- pydantic for defining our data extraction schema
- Atlassian Python API Jira for creating Jira tickets programmatically
- python-dotenv for managing environment variables securely
To get started, set up your development environment by creating a project folder and initialising a virtual environment:
python -m venv venvThen, we activate the virtual environment and install the required dependencies:
pip install llama-extract python-dotenv atlassian-python-api pydantic
In the same directory, create a new file named report_analyser.py. We’ll start by importing the required modules and loading environment variables from an .env file. Add the following code to get started:
from llama_extract import LlamaExtract # Used to call the LlamaExtract API
from llama_cloud.core.api_error import ApiError # Used to catch errors in the agent creation code
from pydantic import BaseModel, Field # Used to create the data extraction schema
from dotenv import load_dotenv # Used to load credentials from via .env files
from atlassian import Jira # Used to call the Jira API
import os # Used to read credentials from environment variables (loaded via .env)
load_dotenv()Before building our AI agent, we need to define a data schema using the pydantic module. Pydantic is a Python library that enables easy data validation and schema configuration through type annotations. It allows you to define data models using standard Python classes and automatically validates input based on the specified types.
This makes it especially valuable for applications requiring data schemas to govern the packaging and structuring of data extracted from unstructured reports. At its core, LlamaExtract relies on Pydantic classes: you define a data model with Pydantic, and LlamaExtract ensures the LLM output conforms to that structure.
We’ll define the following schema using Pydantic:
class Finding(BaseModel):
"""A penetration testing finding outlining the details of found vulnerabilities and remediatiom recommendations"""
id: str = Field(default=None, description= "A unique identifier for the finding, often a number but may also contain letters")
summary: str = Field(default=None, description="A summary or title of the pentest finding")
severity: str = Field(default=None, description="The severity rating of the finding, typically expressed using critical, high, medium, low or informational as a value")
description: str = Field(default=None, description="The text explaining the finding, containing steps to reproduce. All text must be extracted verbatim")
recommendation: str = Field(default=None, description="The text proposing recommendations on how to fix the issue identified in the finding. All text must be extracted verbatim")
class Report(BaseModel):
"""A report containing a list of penetration testing findings"""
findings: list[Finding]
The Pydantic code defines a data schema for structuring penetration testing reports. The Finding model represents individual security findings, each with attributes such as a unique id, a summary, severity level, detailed description and a recommendation for remediation. The Report model groups these findings into a findings list.
This schema ensures that each report is a well-structured collection of validated vulnerability entries, making the data more consistent for our agent to process. As mentioned earlier, LLMs use JSON schemas from Pydantic to guide data extraction. To enhance the accuracy of the extracted data, it’s beneficial to include natural-language descriptions of objects and fields. Pydantic supports this through docstrings and Field descriptions.
Next, we will create our pentest report analysis agent with just a few simple lines of code:
extractor = LlamaExtract()
try:
agent = extractor.create_agent(name="report-parser", data_schema=Report)
except ApiError:
agent = extractor.get_agent(name="report-parser")
result = agent.extract("report.pdf")
This Python snippet leverages LlamaExtract to convert unstructured file data into a structured format based on our predefined schema. First, it initialises the extractor with LlamaExtract(). Then, it attempts to create a new extraction agent within the LlamaCloud agent management platform. It names the agent “report-parser” and uses the Report schema as the data extraction reference schema. If the agent already exists, an ApiError is raised and the existing agent is retrieved instead. Finally, the script instructs the agent to analyse pentest reports titled “report.pdf” and stores the extracted structured data in the result variable.
Building the JIRA upload code
Next, we must write the code that uploads the extracted findings to Jira. For this, we’ll use the atlassian-python-api library, a user-friendly Python wrapper around Atlassian’s official REST APIs. This module simplifies interactions with Jira, making it easy to automate ticket creation tasks. Specifically, we’ll be working with the Jira module.
Before implementing the upload logic, configure a custom issue type called Security in your Jira project. To do this, go to your project homepage, open Project settings, navigate to Issue types, and click Add issue type. Instead of selecting a suggested type, click Create issue type, name it Security, choose an icon, and click Create. Once the issue type is created, the configuration screen will appear. In the right-hand menu, use the search bar to find the Priority field and drag it into the Context fields section. Assuming you have admin permissions, this setup should only take a few minutes. The GIF below demonstrates the process:
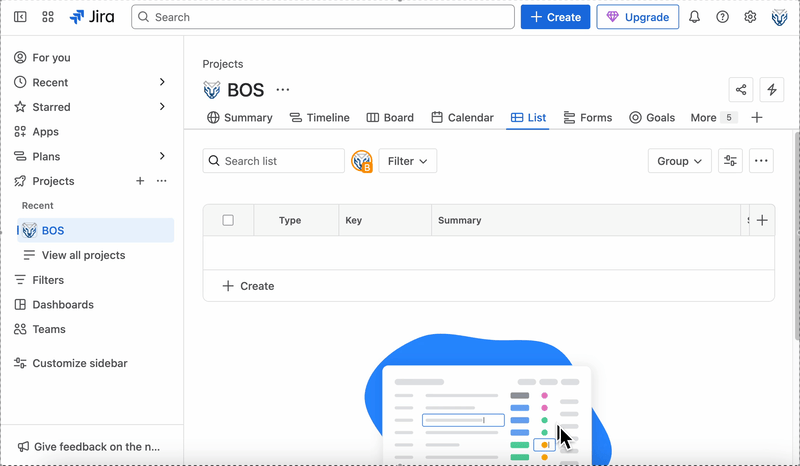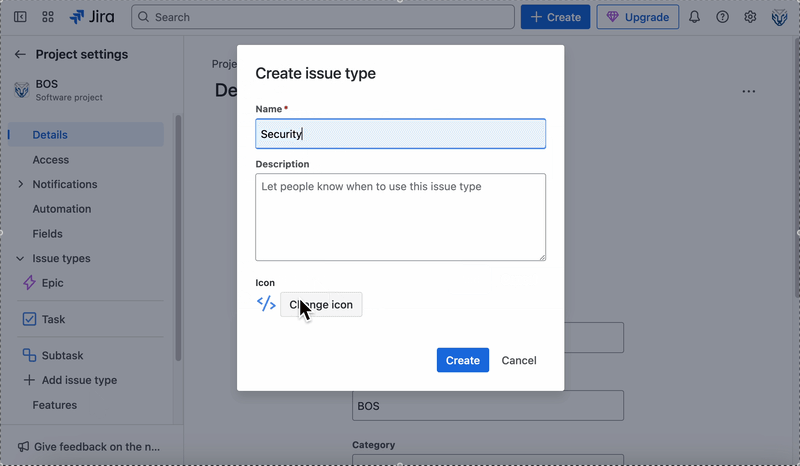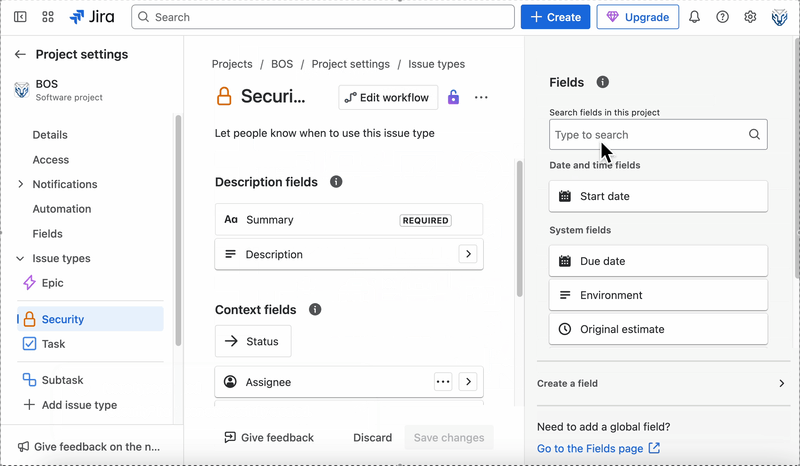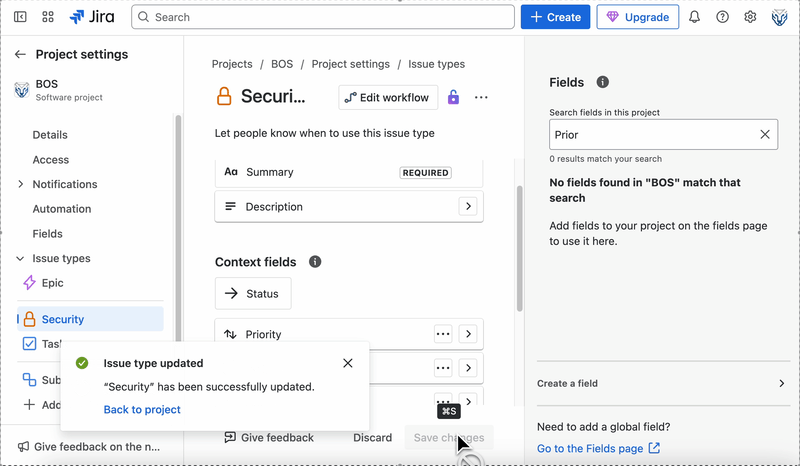
With the Security issue type now set up in Jira, we can write the script that uploads our extracted findings. Here’s how to get started with the Jira integration:
jira = Jira(url=os.getenv("JIRA_URL"), username=os.getenv("JIRA_USERNAME"), password=os.getenv("JIRA_API_KEY"))
priority_mapping = {
"critical":"Highest", "high":"High",
"medium":"Medium", "low":"Low",
"informational":"Lowest", "information":"Lowest",
"info":"Lowest"
}
for row in result.data["findings"]:
jira.issue_create(
fields={
"project": {"key": os.getenv("JIRA_PROJECT_ID")},
"issuetype": {"name": "Security"},
"summary": row["summary"],
"description": row["description"] + row["recommendation"],
"assignee": "Unassigned",
"priority": {"name": priority_mapping[row["severity"].lower()]}
})
print("Uploaded issue:", row["id"])
This Python snippet connects to Jira and automates the creation of security issues based on the extracted findings. The jira object is initialised using credentials and the Jira instance URL, all securely loaded from environment variables via dotenv. This approach keeps sensitive information like API tokens out of the source code.
The priority_mapping dictionary translates severity levels from the extracted findings (critical, medium etc.) into Jira’s corresponding priority labels. This ensures consistency with Jira’s priority naming conventions and allows the data to be formatted for submission as a Security ticket.
The for loop iterates over each finding in result.data["findings"], creating a new Jira issue for each. Key fields such as project ID, issue type, summary, and description are populated, with the description being combined with the recommendation to provide complete context. The priority is mapped using the previously defined dictionary. Each successful issue creation is logged with a print statement that references the ID of the corresponding finding.
Running the agent
After creating the agent and adding the Jira upload code, the script is nearly complete. The final step is to create an .env file in the script directory to store the necessary credentials to run our agent-based report analyser. To do this, we need to add the following credentials to the .env file:
LLAMA_CLOUD_API_KEY=
JIRA_PROJECT_ID=
JIRA_URL=
JIRA_USERNAME=
JIRA_API_KEY=
To create an API key for running the LlamaExtract agent, sign up for an account at cloud.llamaindex.ai. Once logged in, select the API Keys option from the left-hand menu. Then, click Generate New Key to retrieve your LlamaCloud key. Finally, add the key to the .env file after the LLAMA_CLOUD_API_KEY value.
To configure the credentials required for the Jira upload functionality, we must create a personal API key as outlined here. Add the generated key to the JIRA_API_KEY value. Next, to complete the Jira credential setup, add your Jira username (usually your email address) to the JIRA_USERNAME value, followed by the JIRA_URL and JIRA_PROJECT_ID values.
Once the credentials are configured, the agent-based pentest report analyser is ready. You can run it with the command python report_analyser.py. If you’d like, you can test the agent’s performance using this repository of public pentest reports. If everything is set up correctly, the code will automatically provision a data extraction agent on LlamaCloud, extract all pentest findings, and upload them to Jira as shown in the GIF below:
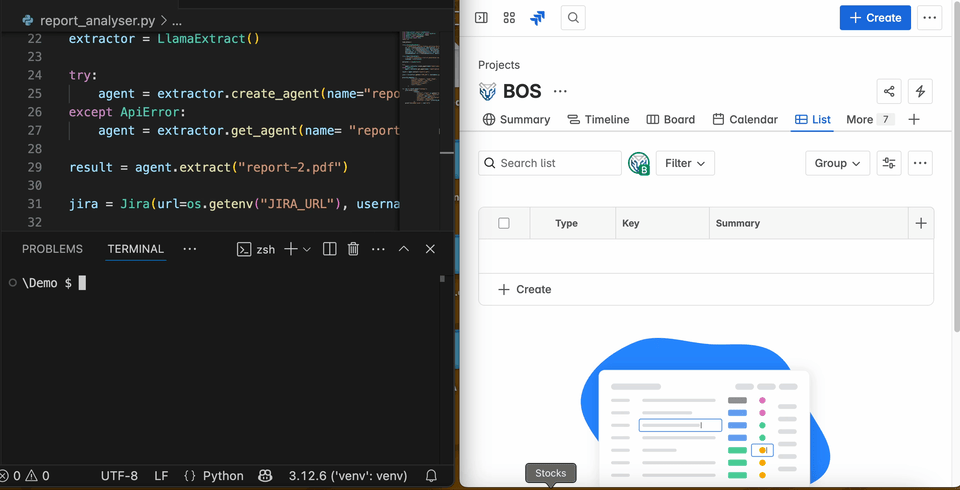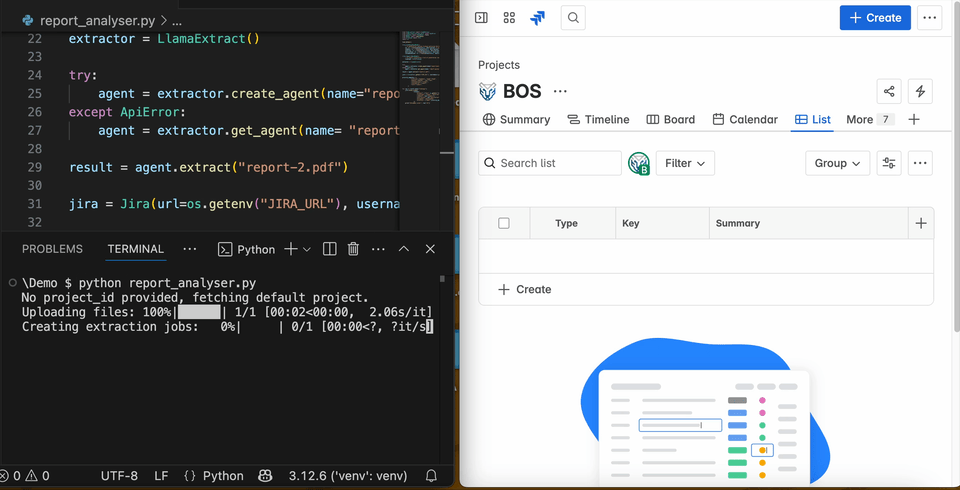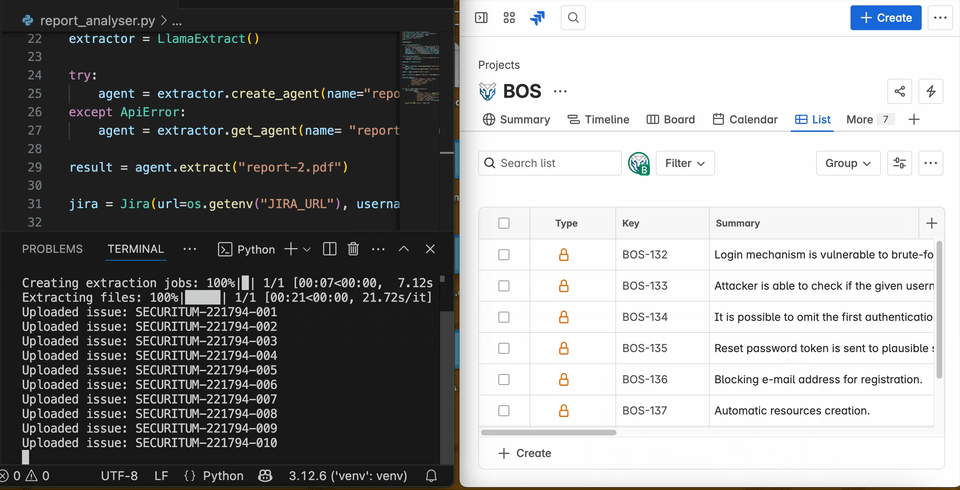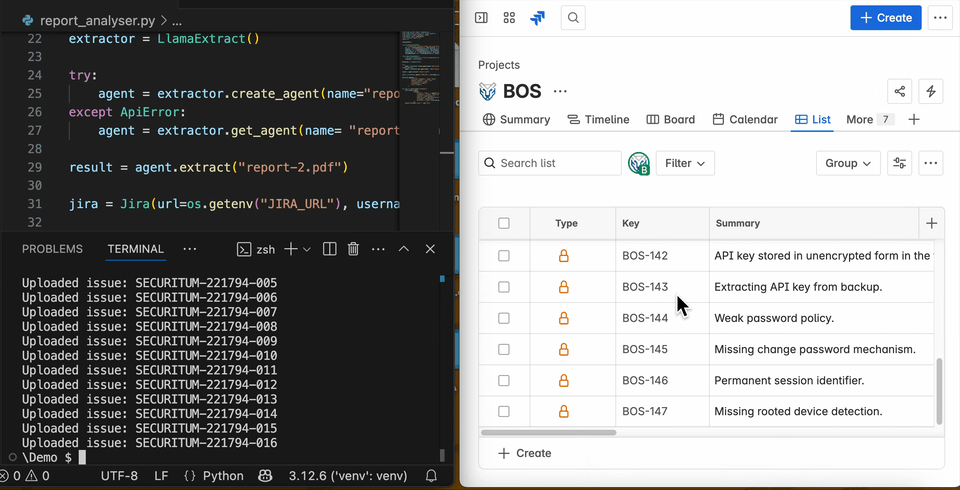
n all subsequent rounds, the script will reuse the same AI agent to reduce costs and speed up parsing and analysis. By default, LlamaExtract will provision the agent and configure an extraction mode. Extraction modes allow us to optimise the agent’s performance for either speed or accuracy. There are three available extraction modes:
- Fast: Costs 5 credits per page and is ideal for quick extraction tasks that are text-based and do not require OCR or tables.
- Balanced: Costs 10 credits per page and is best suited for extraction jobs requiring OCR or for files with complex layouts.
- Multimodal: Costs 20 credits per page and is designed for extraction jobs involving files with many images.
Balanced mode should always be sufficient. Additionally, as of April 2025, LlamaExtract offers 10,000 free credits, which is a very generous free tier for data extraction jobs.
Conclusion
By employing this simple script, we’ve significantly reduced the time spent manually extracting findings from pentest reports and creating Jira tickets. On average, it takes just a few minutes to extract findings from reports and generate the needed Jira ticket. In the next parts of this series, we’ll enhance the script in several ways:
- Using GitHub Actions to make the script easily accessible to the entire team, automating the process even further.
- Implementing a locally installed, private LLM to save costs and address privacy concerns associated with sending confidential reports to third-party services.
- Implementing a shared folder for the upload and download of reports, simplifying file management.
- Extending the script to handle audit findings, broadening its capabilities.
- Extending the agent to analyse existing pentest Jira tickets and automatically closing issues that were risk-accepted in the past.
These improvements will make the system more efficient, cost-effective and secure when automating the pentest report analysis process and Jira integration.



